14 March 2025
AWS Lambda
It is a serverless compute service that allows you to run code without provisioning or managing
servers. With AWS Lambda, you can run your code in response to events like changes in data,
application states, or requests, and it automatically scales the application by running the code in
parallel. It is designed to handle small, quick tasks efficiently, making it ideal for use cases like
processing web scrapes, which are not resource-intensive and do not require constant server
availability.
Configuration
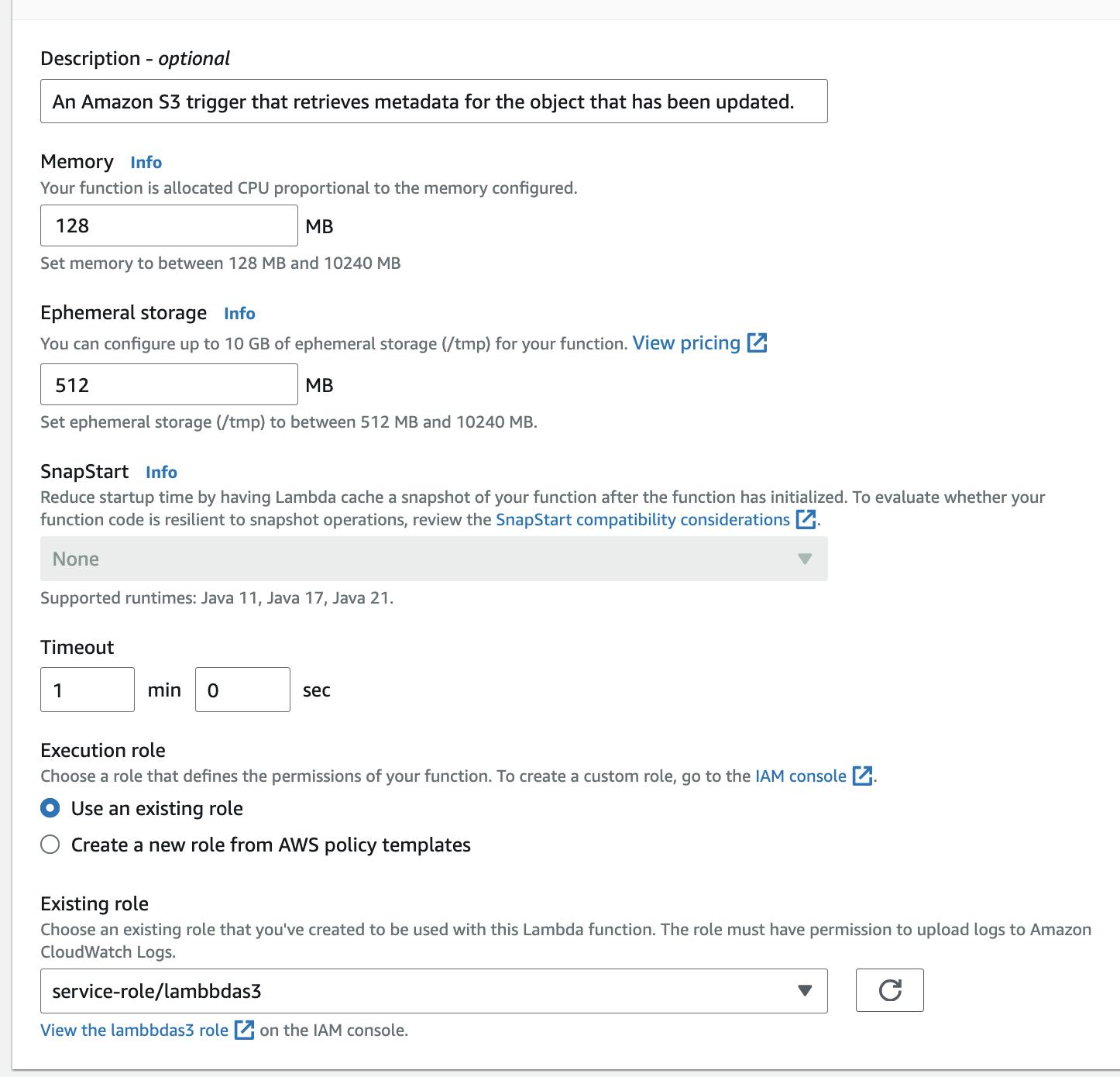
The basic settings for an AWS Lambda function:
- Memory: This is the maximum memory the function can use during execution. It significantly affects your costs, so set it according to your needs.
- Ephemeral Storage: Think of this like your computer’s hard drive – used to save files temporarily during execution. It has a minimal impact on pricing, so you can increase it beyond your need also.
- Timeout: This is the maximum time the function can run before it’s automatically stopped. You can set it up to 15 minutes, and it also has a big impact on costs.
- Role: The role is like a set of permissions that the Lambda function uses to interact with other AWS services. It defines what the function is allowed to do, such as reading from an S3 bucket, writing logs to CloudWatch, or accessing a database. This is important for security, ensuring the function only has the permissions it needs to perform its tasks.
AWS EventBridge
It is a serverless event bus service that makes it easier to build event-driven applications at scale. It allows connecting different AWS services or external applications and route events to Lambda functions, ensuring that functions are invoked automatically based on specified schedules or events.
In our case, if we use AWS EventBridge for scheduling. This means that EventBridge will automatically invoke our Lambda function at predefined intervals, ensuring that our scraping tasks are performed regularly without requiring manual intervention or server management.
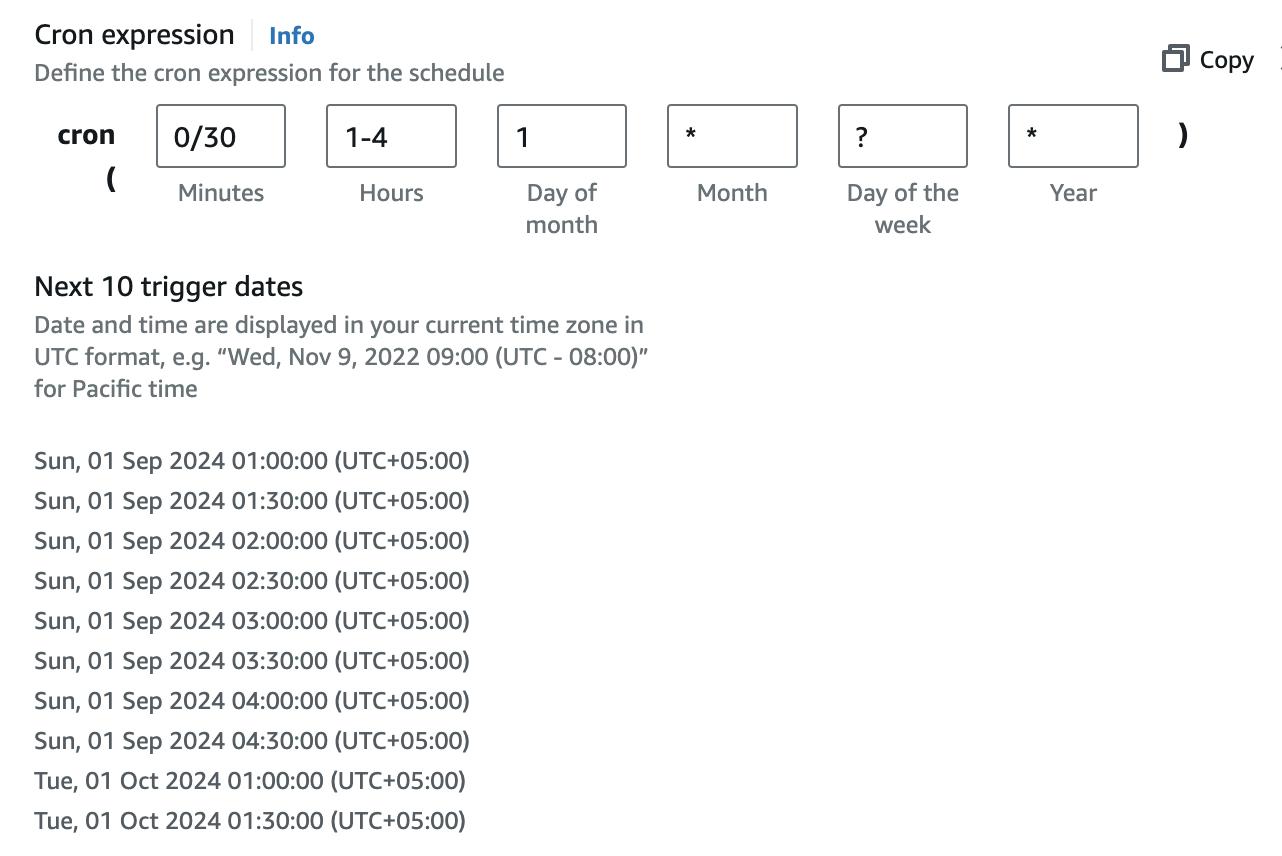
Specify run schedule
Here’s an example of a schedule to run on the first day of the month every 30 minutes. This will result in 48 invocations. If parsing a single URL takes a maximum of 10 seconds, including sleep time, then a 5-minute invocation can parse 50 pages. We can parse 4,800 URLs in a day at that rate. Please note that the maximum invocation duration is 15 minutes. For more details, see the AWS Lambda section, and check the costing section for the impact on billing.
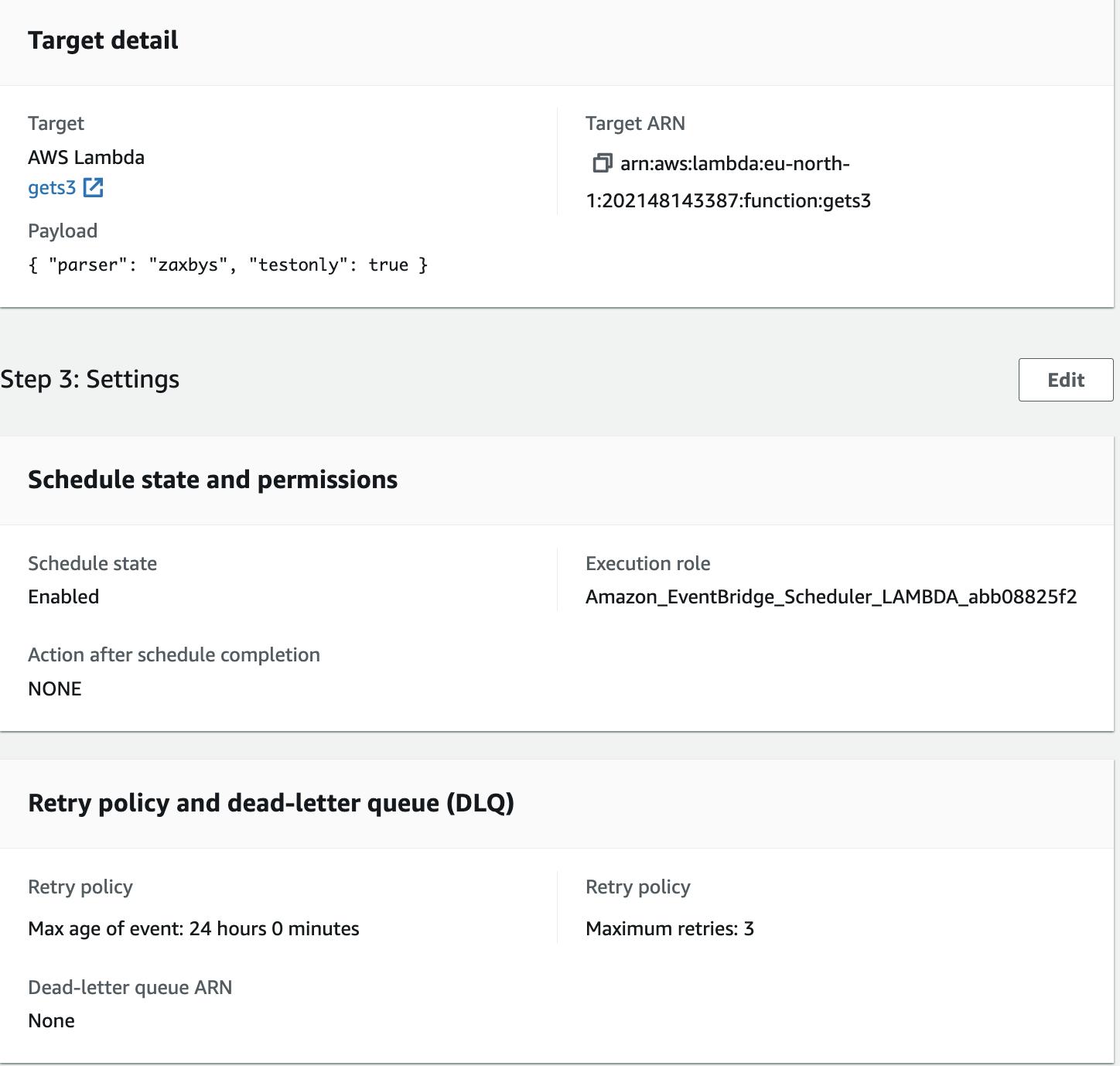
Other settings
It specifies which function to invoke and what parameters to pass. The function uses these parameters to decide what tasks to perform. We can either create separate functions and schedulers for each parser or have one main function that handles all parsers, using payload values to determine the specific action for AWS Lambda.
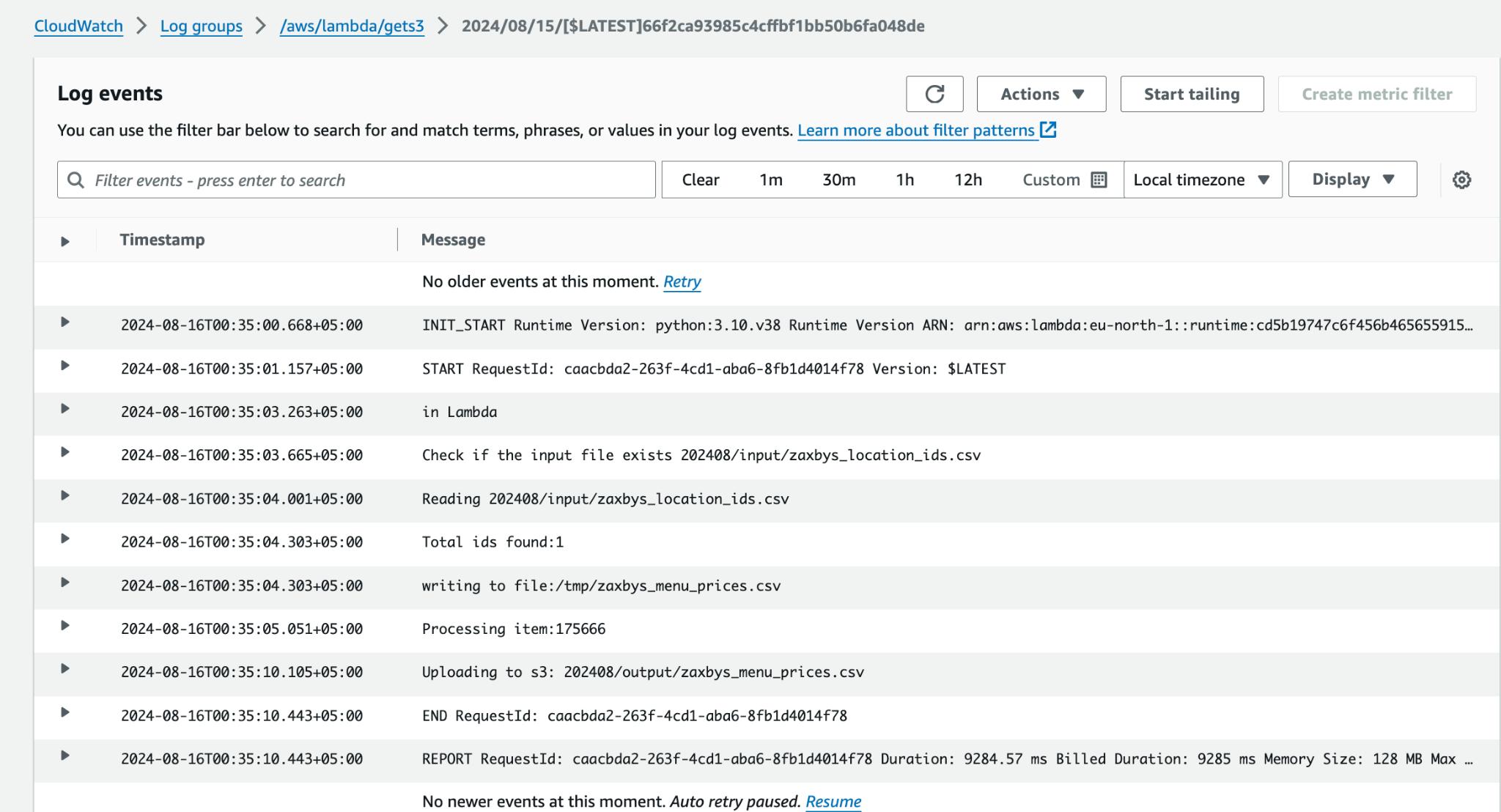
Logs with execution details are managed on cloudwatch

Data Processing Strategy
Currently, your approach involves consuming all the files and converting them to a final CSV on the fly, which leads to the loss of hierarchical information and limits your ability to re-run experiments on the data. A better approach would be to:
- Save Raw JSON or a Less Processed CSV: By saving the raw JSON or a less processed CSV, you preserve the original data's richness and structure. This allows you to reprocess the data as needed
- Reprocess Data Using AWS Glue: AWS Glue is a fully managed ETL service that can be used to clean, enrich, and transform your data. You can use Glue to convert the raw JSON or CSV into a more structured format or to apply new processing rules as required.
- Scale Processing with Apache Spark: If you have large datasets or need to perform complex processing, you can use Apache Spark in conjunction with AWS Glue to distribute the processing load across multiple nodes, ensuring efficient and scalable data processing. I worked with data having hundred of millions of records on Apache spark and it worked like charm. For this we will setup an AMI with required installation and on
need basis we will start an EC2 instance and if we go for cost cutting then we start spot instance (which is volatile by nature but is 3 three times cheaper than regular instance). We will execute our job and experiments, since our data is already on S3 and push the results back to S3.
This strategy not only enhances data integrity and flexibility but also aligns with your goal of efficiently managing resources and costs.
Let’s suppose we run some analysis on our CSV file and find the following inconsistencies.
- sub-category: 33 missing values.
- sub-subcategory: 124 missing values.
- calories: 14 missing values.
- parent_price: 124 missing values.
- description: 157 missing values.
Now we worked on out processing technique and come up with resolution now to check our improvement we only reparse client site and check the impact of out changes and if we need to do this for 10 time then. So if we have raw data then we will be in good shape to run test as many times as we want.
Suggested Model
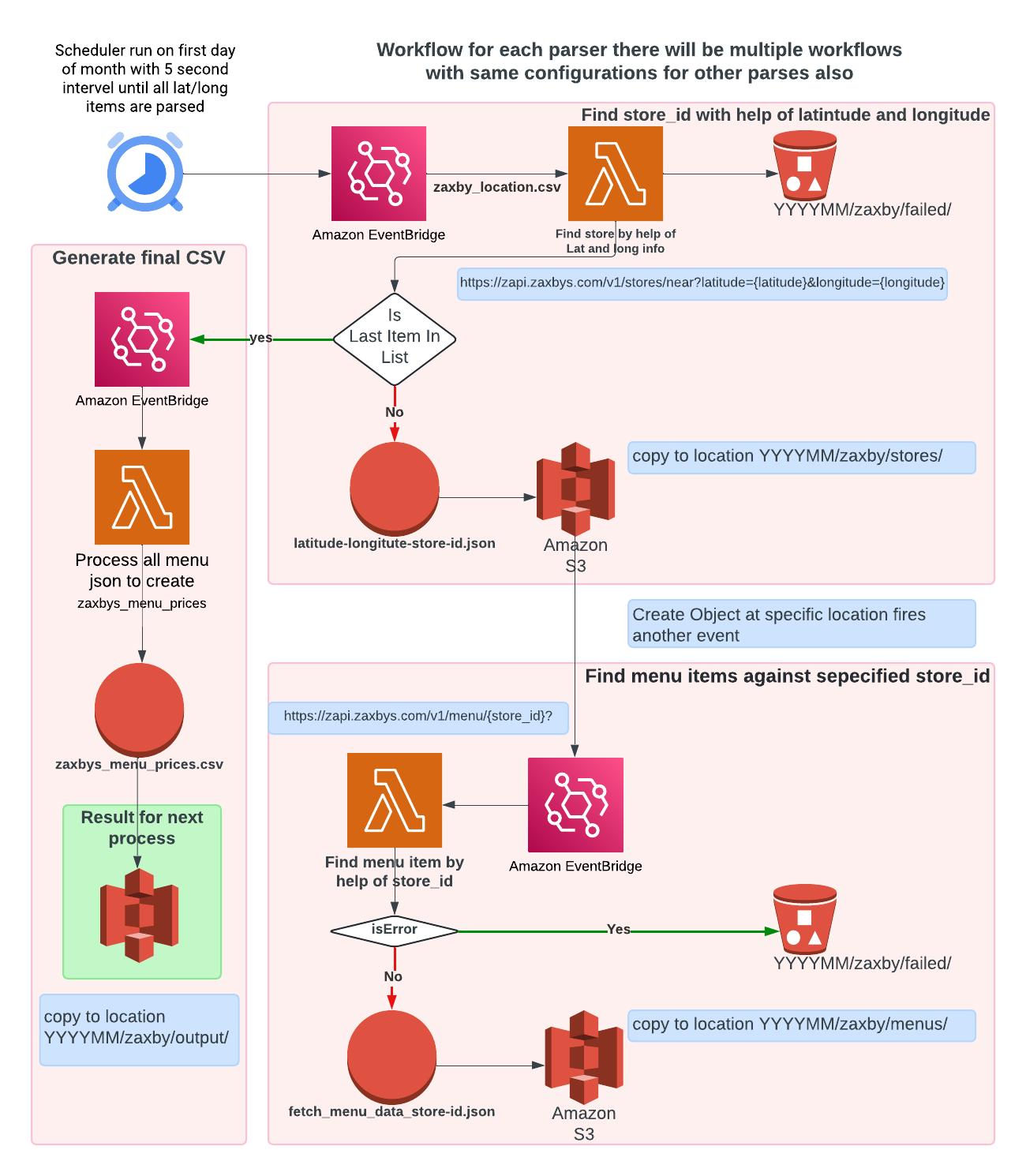
Why Not Use EC2?
1. Over-Provisioning Resources
- Resource Efficiency: EC2 instances are typically designed for long-running tasks or applications that need to be up 24/7. In your case, the web scraping tasks are intermittent and not resource-intensive. Running an EC2 instance continuously would mean paying for compute resources even when they are not in use, leading to over-provisioning.
- Cost Inefficiency: With EC2, you would have to pay for the instance as long as it is running, regardless of whether it is performing tasks. You would be paying for CPU, memory, storage, and network resources even during idle times, which is not cost-effective for a task that runs only intermittently.
2. Manual Management
- Start/Stop Complexity: If you use EC2, you would need to manually start and stop the instance to run your scraping tasks. This requires additional management overhead and increases the complexity of your operations. With AWS Lambda, your code runs only when needed, without requiring any manual intervention.
- Scaling Challenges: EC2 requires manual scaling or setting up Auto Scaling groups. For tasks like web scraping, which may vary in frequency, manually managing the scaling of EC2 instances can be cumbersome. Lambda, on the other hand, automatically scales based on the number of events, handling any spikes in demand seamlessly.
3. Serverless Advantages
- Automatic Scaling: AWS Lambda automatically scales based on the number of requests, making it ideal for workloads that are unpredictable or have varying demand.
- Pay-as-You-Go Pricing: Lambda charges are based on actual usage, meaning you only pay for the compute time when your code is running. This is particularly beneficial for tasks like web scraping that do not require continuous processing.
Cost Calculation for 50,000 hits per month
Ref: https://aws.amazon.com/lambda/pricing/
Given Scenario:
- Total Hits per Month: 50,000
- Hits per Invocation: 50
- Total Invocations per Month: 50,000 / 50 = 1,000
- Estimated Memory Usage: 128 MB
- Estimated Execution Time per Invocation: 10 minutes (600 seconds)
Pricing Calculation:
1. Request Charges:
-
-
-
- Total Lambda Invocation Requests = 1,000
- Cost for Requests = (1,000 / 1,000,000) * $0.20 = $0.0002
-
-
2. Compute Charges:
-
-
-
- Memory Allocated = 128 MB
- Execution Time per Invocation = 600 seconds
- Total Compute Time = 1,000 invocations * 600 seconds = 600,000 seconds
- Total Compute Cost = 600,000 seconds * 128 MB * $0.0000166667 per GB-
second
-
-
3. Total Monthly Cost:
-
-
-
- Total Monthly Cost = Request Charges + Compute Charges = $0.0002 + $1.25 =
$1.2502
- Total Monthly Cost = Request Charges + Compute Charges = $0.0002 + $1.25 =
-
-
Even the smallest EC2 instance running continuously would cost significantly more than AWS Lambda for your use case. Additionally, with EC2, you'd be paying for idle time and potentially over-provisioned resources, whereas Lambda charges only for actual usage, making it far more cost-effective for your needs.
My Reservations
Scraping content behind a VPN can be a significant challenge, often resulting in continuous blocking of IP addresses, making the process unstable and unreliable. Instead, we can focus on parsing publicly available content like RSS feeds and HTML pages. This approach is much more sustainable and aligns with what search engines do to provide accurate and up-to-date results. Plus, since we're using AWS Lambda, our execution costs are minimal, allowing us to run our parsers without budget concerns. In the rare case that a parser fails, we can update it within a day or two, but if our IPs are continuously blocked, it would cause substantial disruptions to our operations. By prioritizing public data sources, we ensure a more consistent
and scalable solution.
VPN Cost
There is a hidden cost associated with maintaining VPN servers or using web proxies, adding to the complexity and expense. I used scrapeops.io which provided 1000 free calls per month but for zaxbys only we need atleast 2000 calls to download store locations and store menus. Similarly for other stores too.
On the other hand If we are parsing open available content and not putting extra load then we are simply a web spider which is accepted norm in technical world.
Handle Errors [todo]
If execution of any function raises exception then tell the owner through email with cloudwatch link and some how halt the scheduler to stop sending event.
Parsers Validation: [todo]
Jesus Delintt:Also, this is a good time to tell you that if there is an error in running the web API then we need to know if there was an issue. That way you or I can see if the url has changed.
I am listing the process to create a job to notify owners if there's an error when running the web API.
Gather a list of URLs and their corresponding parsers.
- Use an HTTP client (e.g., requests in Python) to send a GET request to each URL.
- Store this information in a structured format, such as a CSV file or a database.
- Check the HTTP status code to ensure the URL is accessible (e.g., status code 200).
- If the URL is accessible, use the corresponding parser to extract the necessary data.
- Handle any parsing errors and log them for review.
- Store the results of the URL checks and parsing attempts.
- Include details such as:
- URL
- HTTP status code
- Parsing success/failure
- Error messages (if any)
- Compile the results into a report format, such as a table.
- The report should summarize the success and failure rates, and provide details on any
issues encountered. - Setting up a separate scheduled task.
- This will automate the process of checking URLs, parsing, and sending the status email
at defined intervals.
Stop Scheduler [todo]
Once all the ids are scraped then tell the scheduler to stop sending events.