29 January 2025
Introduction
DeepSeek has rapidly emerged as a groundbreaking force in the artificial intelligence (AI) industry, offering open-source models that challenge proprietary AI systems in performance, accessibility, and cost-efficiency. DeepSeek-V3 is an Open-Source 671B parameter Mixture-of-Experts (MoE) model with 37B activated parameters per token. It features innovative load balancing and multi-token prediction, trained on 14.8T tokens. The model achieves state-of-the-art performance across benchmarks while maintaining efficient training costs of only 2.788M H800 GPU hours. It incorporates reasoning capabilities distilled from DeepSeek-R1 and supports a 128K context window. From its origins to its latest innovations like DeepSeek-V3 and DeepSeek-R1, this blog provides a deep dive into DeepSeek’s history, technical advancements, API access, pricing, and comparisons with other open-source models.
History of DeepSeek
DeepSeek was founded by Liang Wenfeng, a tech visionary from China with a background in AI-driven stock market investments. His success with High-Flyer Quant allowed him to invest in high-performance AI hardware, such as Nvidia GPUs, ultimately leading to the creation of DeepSeek. By 2023, DeepSeek introduced AI models that rivaled leading proprietary models while adhering to a philosophy of open access and fair pricing.
DeepSeek Model Family
DeepSeek-V3: The Mixture-of-Experts Model
DeepSeek-V3 is a state-of-the-art Mixture-of-Experts (MoE) language model featuring 671 billion total parameters, with 37 billion activated per token. Key innovations in DeepSeek-V3 include:
- Multi-Head Latent Attention (MLA): A novel mechanism improving inference efficiency.
- DeepSeekMoE Architecture: Enhances cost-effective training through specialized experts.
- Multi-Token Prediction (MTP): Improves performance by pre-planning representations.
- Efficient Training: Pre-trained on 14.8 trillion high-quality tokens with 2.788M H800 GPU hours.
- Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL): Optimizes reasoning, factuality, and alignment with human preferences.
Despite its immense scale, DeepSeek-V3’s training cost was just $5.576 million, significantly lower than many proprietary models.
DeepSeek-R1: Reinforcement Learning for Reasoning
DeepSeek-R1 is a specialized reasoning model trained purely through Reinforcement Learning (RL) without relying on supervised fine-tuning (SFT). Key highlights:
- DeepSeek-R1-Zero: Developed through pure RL, achieving strong reasoning capabilities.
- DeepSeek-R1: An enhanced version with a multi-stage training process incorporating a small amount of cold-start data.
- Performance: Achieves 79.8% Pass@1 on AIME 2024, surpassing OpenAI-o1-1217.
- Distillation: Smaller models (1.5B, 7B, 8B, 14B, 32B, 70B) derived from DeepSeek-R1 outperform many open-source counterparts.
DeepSeek-R1 showcases how reinforcement learning alone can unlock advanced reasoning capabilities, setting a new standard for future AI research.
API Access
DeepSeek provides a robust API for developers, enabling seamless integration into applications for various AI tasks such as text generation, code completion, and reasoning.
To use DeepSeek’s API, developers must obtain an API key and use the following base URLs:
- Base URL: https://api.deepseek.com
- OpenAI-Compatible API: platform.deepseek.com
- Getting Started with the DeepSeek API : API Key
Example API call using python:
# Please install OpenAI SDK first: `pip3 install openai`
from openai import OpenAI
client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False
)
print(response.choices[0].message.content)
Pricing & Billing
DeepSeek follows a pay-per-token pricing model. The following are the pricing details for DeepSeek’s models:
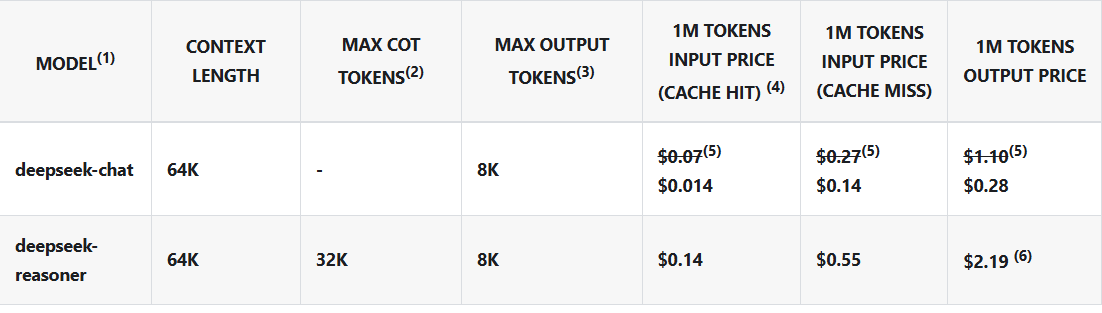
- Discount: DeepSeek offers promotional discounts until February 8, 2025.
- CoT (Chain of Thought) Tokens: deepseek-reasoner charges for both reasoning and final output tokens equally.
- Billing: Usage is deducted from your account balance based on token consumption.
Accessibility and Future Developments
DeepSeek-V3 is openly available for research and development. It can be accessed via:
- Hugging Face: deepseek-ai
- Github: deepseek-ai
- Official Chat Platform: Live demonstration at chat.deepseek.com.
With continuous enhancements in Multi-Token Prediction and inference optimizations, DeepSeek-V3 remains at the frontier of open-source AI, competing with the best closed-source models in the market.
Why Choose DeepSeek?
- Open-Source Advantage: Unlike proprietary models (GPT-4, Claude 3.5), DeepSeek offers transparency and community-driven improvements.
- Cost-Effectiveness: Training and API costs are significantly lower than closed-source alternatives.
- High Performance: Benchmarks show DeepSeek’s capabilities rivaling top-tier AI models.
- Scalability & Customization: Developers can fine-tune DeepSeek models for specific use cases, providing greater flexibility.
- Extensive Deployment Options: Runs on diverse hardware setups, from consumer GPUs to cloud clusters.
Performance Comparison with Other Open-Source Models
DeepSeek’s models have been benchmarked against industry-leading open-source and closed-source models, demonstrating competitive or superior performance.
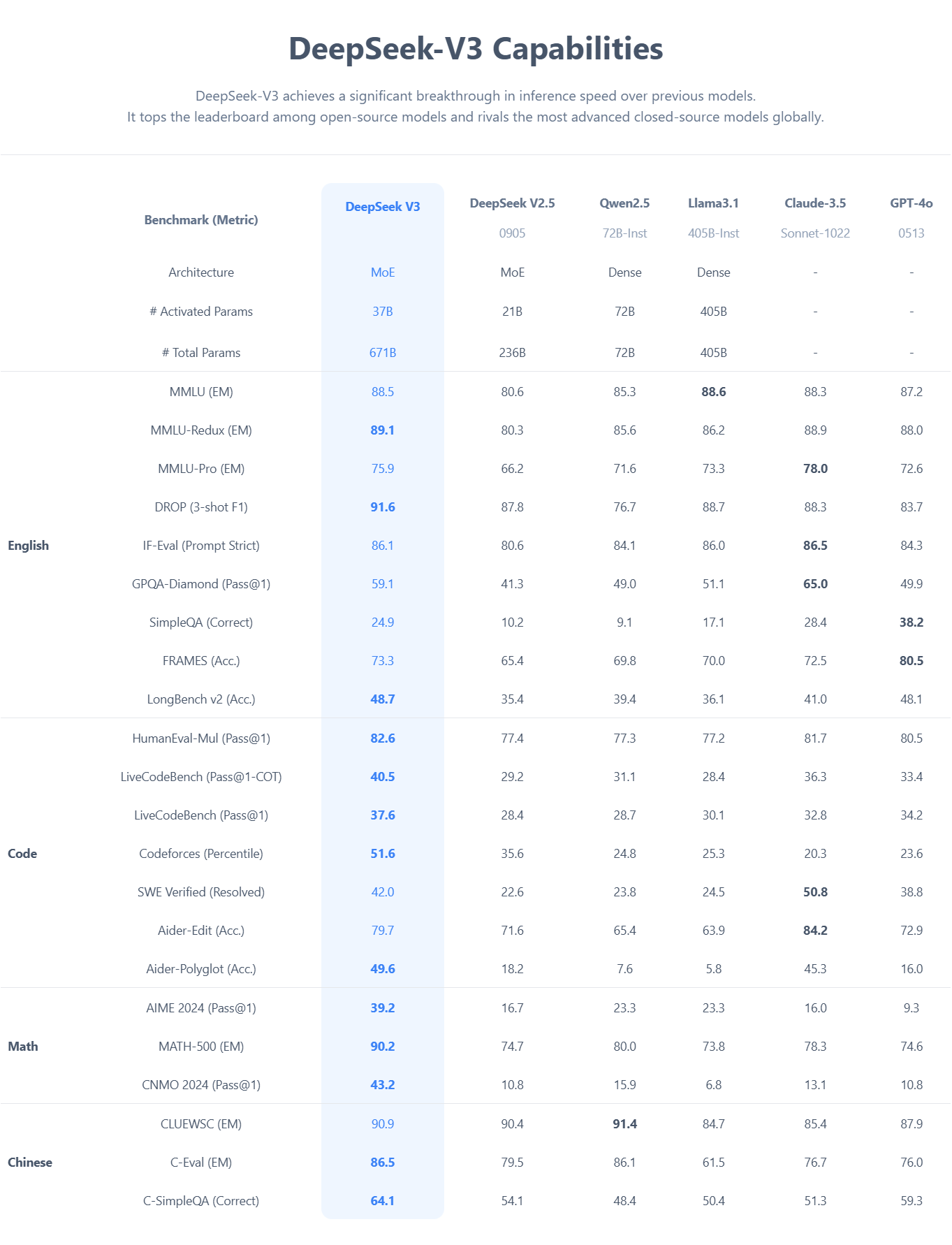
DeepSeek-V3 sets a new benchmark in open-source AI, outperforming many competitors in language understanding, coding, and mathematical reasoning. With 88.5% accuracy on MMLU, 82.6% HumanEval Pass@1, and a 90.2% score on MATH-500, it rivals even the most advanced proprietary models. Its Mixture-of-Experts (MoE) architecture enables exceptional efficiency, activating only 37B parameters per token while maintaining state-of-the-art performance. Whether in complex reasoning (DROP 91.6%), real-world programming (LiveCodeBench 40.5%), or multilingual tasks (C-Eval 86.5%), DeepSeek-V3 proves to be a powerful, open-source alternative to leading AI systems.
Conclusion
DeepSeek-V3 is not just an incremental update, it represents a paradigm shift in AI model design, proving that open-source models can rival or even surpass closed-source alternatives like OpenAI’s GPT and Anthropic’s Claude. By leveraging Mixture-of-Experts (MoE) architecture, DeepSeek-V3 balances efficiency with performance, activating only a fraction of its total parameters per token while maintaining state-of-the-art capabilities in reasoning, coding, and natural language understanding.
As open-source AI continues to gain momentum, DeepSeek-V3 sets a new benchmark, challenging the notion that only large-scale proprietary models can lead in innovation. With ongoing improvements in inference optimization, accessibility through APIs, and an active research community, DeepSeek-V3 is poised to shape the next wave of AI advancements. With its commitment to open-source excellence, DeepSeek invites developers and enterprises to explore its capabilities and be part of AI’s next frontier.


