Introduction to ETLs and Orchestration
In today’s data-driven world, businesses need a structured approach to managing and processing vast amounts of data. This is where ETL (Extract, Transform, Load) processes come into play. ETL helps organizations systematically collect, refine, and store data for further analysis and decision-making.
- Data is retrieved from various sources, including relational databases, APIs, flat files, and cloud storage systems like AWS S3 or Google Cloud Storage.
- The extracted raw data undergoes cleansing, validation, and formatting to meet the required standards. This step may include filtering unwanted data, aggregating information, or applying business rules.
- The transformed data is then loaded into a target data warehouse, data lake, or database for further analytics, reporting, or machine learning applications.
It’s important to understand that ETL is the process, while orchestration refers to the coordination and automation of that process. Orchestration tools like Dagster help ensure that the steps of an ETL workflow are:
- Executed in the correct order with dependencies handled properly.
- Automatically retried or flagged when failures occur.
- Observable, testable, and easy to debug.
So while ETL defines what needs to happen with the data, orchestration defines how and when it happens, particularly at scale and across many interconnected steps. That’s why we chose Dagster for our ETL workflows—it provides robust orchestration capabilities tailored to data engineering.
Why Use Dagster?
Dagster is an open-source data orchestrator designed to simplify and automate ETL workflows. It provides a structured approach to defining data pipelines and managing dependencies between tasks. Here are some key reasons why Dagster stands out:
- No more running scripts manually. Dagster automates the execution of each step in the workflow.
- Built-in tools allow you to track the execution status of every step, visualize logs, and debug failures effectively.
- Dagster seamlessly integrates with cloud services like AWS, Google Cloud, and Snowflake, making it ideal for processing large datasets.
- Define assets as independent units that can be reused in multiple workflows. For example, the same transformation logic can be applied to multiple datasets without redundant coding.
Setting Up Dagster
1. Setup a virtual environment
- python -m venv dagster-env
- source dagster-env/bin/activate # On Windows, use `dagster-env\Scripts\activate`
2. Install Dagster
- pip install dagster dagster-webserver pandas
3. Run dagster
- Run dagster ui by “dagster dev”
The Example Pipeline
Our pipeline covers:
- Fetching a CSV file from AWS S3.
- Processing raw data and generating summary.
- Loading the data into Snowflake.
1. Setting Up Resources
Resources in Dagster represent external dependencies like databases or cloud storage. Below is the resource setup for AWS S3 and Snowflake.
@resource
def s3_resource(_):
import boto3
return boto3.client(
“s3”,
aws_access_key_id=os.getenv(“YOUR_AWS_ACCESS_KEY”),
aws_secret_access_key=(“YOUR_AWS_SECRET_KEY”),
region_name=”ap-south-1″,
)
@resource
def snowflake_resource():
from dagster_snowflake import snowflake_resource
return snowflake_resource.configured({
“account”: “os.getenv(“SNOFLAKE_ACCOUNT)”,
“user”=os.getenv(“SNOWFLAKE_USER”),
“password”: os.getenv(“SNOWFLAKE_PASSWORD”),
“database”: “FitnessApp”,
“warehouse”: “COMPUTE_WH”,
“schema”: “PUBLIC”,
})
2. Fetching Data from S3
This step involves downloading a CSV file from an S3 bucket and loading it into a Pandas DataFrame for further processing. Metadata logging ensures visibility into the process.
@asset(required_resource_keys={“s3”})
def fetch_csv_from_s3(context):
Import pandas as pd
Import io
bucket = “s3-snow-lambda”
key = “prices.csv”
response = context.resources.s3.get_object(Bucket=bucket, Key=key)
csv_content = response[“Body”].read().decode(“utf-8”)
data_frame = pd.read_csv(io.StringIO(csv_content))
context.log.info(f”Fetched {len(data_frame)} rows from S3″)
context.add_output_metadata({
“DataFrame Preview”: MetadataValue.md(data_frame.head().to_markdown(index=False))
})
return data_frame
3. Processing the Data
After fetching the data, we add a new column called discounted_price by applying a 10% discount to an existing price column. This demonstrates simple data transformation.
@asset(required_resource_keys={“s3”})
def fetch_csv_from_s3(context):
bucket = “s3-snow-lambda”
key = “prices.csv”
response = context.resources.s3.get_object(Bucket=bucket, Key=key)
csv_content = response[“Body”].read().decode(“utf-8”)
data_frame = pd.read_csv(io.StringIO(csv_content))
context.log.info(f”Fetched {len(data_frame)} rows from S3″)
context.add_output_metadata({
“DataFrame Preview”: MetadataValue.md(data_frame.head().to_markdown(index=False))
})
return data_frame
4. Loading Data into Snowflake
The processed data is loaded into a Snowflake table. Temporary stages are used to manage file uploads efficiently.
@asset(required_resource_keys={“snowflake”})
def save_to_snowflake(context, process_data):
df = process_data
temp_file_path = “temp_data.csv”
df.to_csv(temp_file_path, index=False, header=False)
snowflake_stage = “TEMP_STAGE”
snowflake_table = “PRICES”
try:
with context.resources.snowflake.get_connection() as conn:
cursor = conn.cursor()
cursor.execute(f”CREATE OR REPLACE STAGE {snowflake_stage}”)
cursor.execute(f”PUT file://{temp_file_path} @{snowflake_stage}”)
cursor.execute(f”COPY INTO {snowflake_table} FROM @{snowflake_stage} FILE_FORMAT = (TYPE = ‘CSV’ FIELD_OPTIONALLY_ENCLOSED_BY=’\”‘);”)
cursor.execute(f”REMOVE @{snowflake_stage}”)
context.log.info(“Data successfully loaded into Snowflake.”)
except Exception as e:
context.log.error(f”Failed to load data into Snowflake: {e}”)
raise
finally:
if os.path.exists(temp_file_path):
os.remove(temp_file_path)
5. Definitions
Finally, we register resources and assets in Dagster.
defs = Definitions(
resources={“s3”: s3_resource, “snowflake”: snowflake_resource},
assets=[fetch_csv_from_s3, process_data, save_to_snowflake],
)
Running Dagster Pipeline
Now, we can see the Global asset lineage in dagster ui running locally on port 3000
We can materialize an asset by running its job
Our Asset is now materialized and now we can preview the data it has produced
Now lets materialize the Process Data asset
We can now view its meta data too to see the data it has produced
Now, lets move to our final step, which is inputting this transformed data into Snowflake database, lets run our snowflake asset
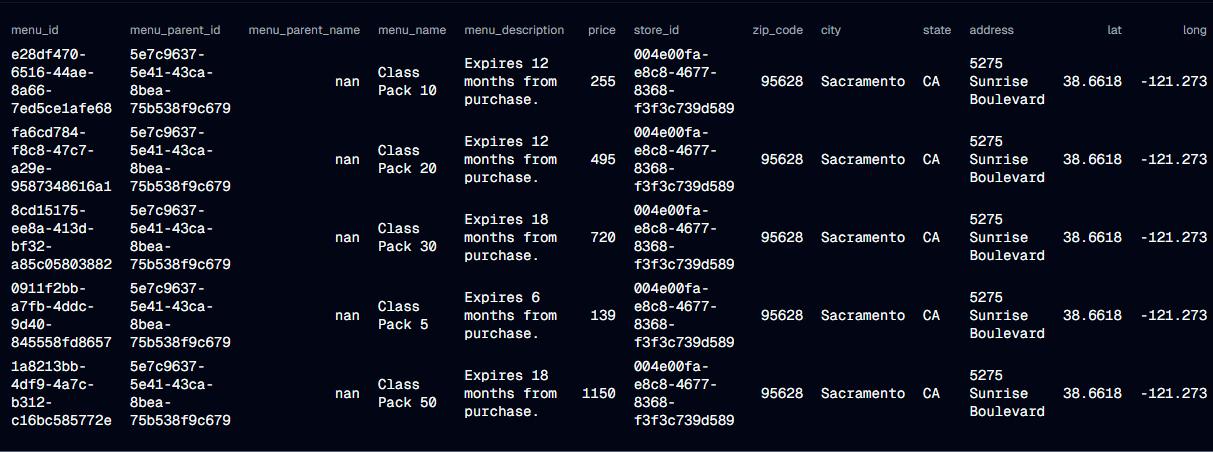
Now, we can verify our data in snowflake cloud
As we can see, our transformation and saving of data has been executed successfully.
Benefits of Using Dagster
- Each step in the pipeline is defined independently, making it reusable and testable.
- Dagster’s rich logging and metadata capabilities provide clear insights into pipeline execution.
- Seamlessly integrates with tools like AWS, Snowflake, and Pandas.
- Allows customization and configuration to meet specific pipeline requirements.
Conclusion
Dagster makes managing complex data pipelines intuitive and efficient. Whether you are working with cloud storage, databases, or data transformations, Dagster provides the tools and flexibility needed for modern data orchestration. Start building your pipelines today and experience the power of Dagster!
