19 March 2025
Introduction
In the competitive restaurant industry, staying ahead often hinges on access to real-time data. Imagine the power of having up-to-date menu information from thousands of locations of different competitors at your fingertips. This data can drive critical business decisions, from pricing strategies to menu optimization. However, the challenge lies in efficiently gathering and processing this data at scale. Traditional methods often fall short, plagued by issues like inconsistent data formats, unreliable execution, and skyrocketing costs. Enter AWS Lambda and EventBridge—a dynamic duo that transforms how we approach web scraping, offering a scalable, cost-effective, and automated solution.
In this blog post, we’ll explore how AWS Lambda and EventBridge can be leveraged to build a robust system for scraping restaurant menu data, ensuring reliability, scalability, and cost efficiency. Whether you’re a data engineer, a business leader, or a tech enthusiast, this guide will provide valuable insights into solving real-world data challenges with cutting-edge cloud technologies.
The Problem: Scaling Data Scraping Without Breaking the Bank
Web scraping, while powerful, is fraught with challenges. From handling diverse data formats to avoiding IP blocks and managing costs, the process can quickly become overwhelming. For businesses in the restaurant industry, the need to scrape menu data across multiple locations adds another layer of complexity. Traditional solutions, such as running dedicated servers (e.g., EC2 instances), often lead to over-provisioning, manual management headaches, and unnecessary expenses.
The ideal solution must:
-
- Scale seamlessly to handle thousands of URLs.
- Run intermittently without incurring costs during idle times.
- Automate scheduling to ensure regular data updates.
- Handle failures gracefully and notify stakeholders.
- Preserve raw data for reprocessing and experimentation.
This is where AWS Lambda and EventBridge shine. Together, they provide a serverless, event-driven architecture that addresses these challenges head-on.
The Solution: AWS Lambda and EventBridge in Action
AWS Lambda: The Power of Serverless Computing
AWS Lambda is a serverless compute service that allows you to run code without provisioning or managing servers. It’s designed to handle small, quick tasks efficiently, making it perfect for web scraping. Here’s why Lambda is a game-changer:
-
- Automatic Scaling: Lambda runs your code in parallel, scaling automatically to handle spikes in demand.
- Cost Efficiency: You pay only for the compute time your code uses, with no charges for idle time.
- Ease of Use: Lambda integrates seamlessly with other AWS services, simplifying your architecture.
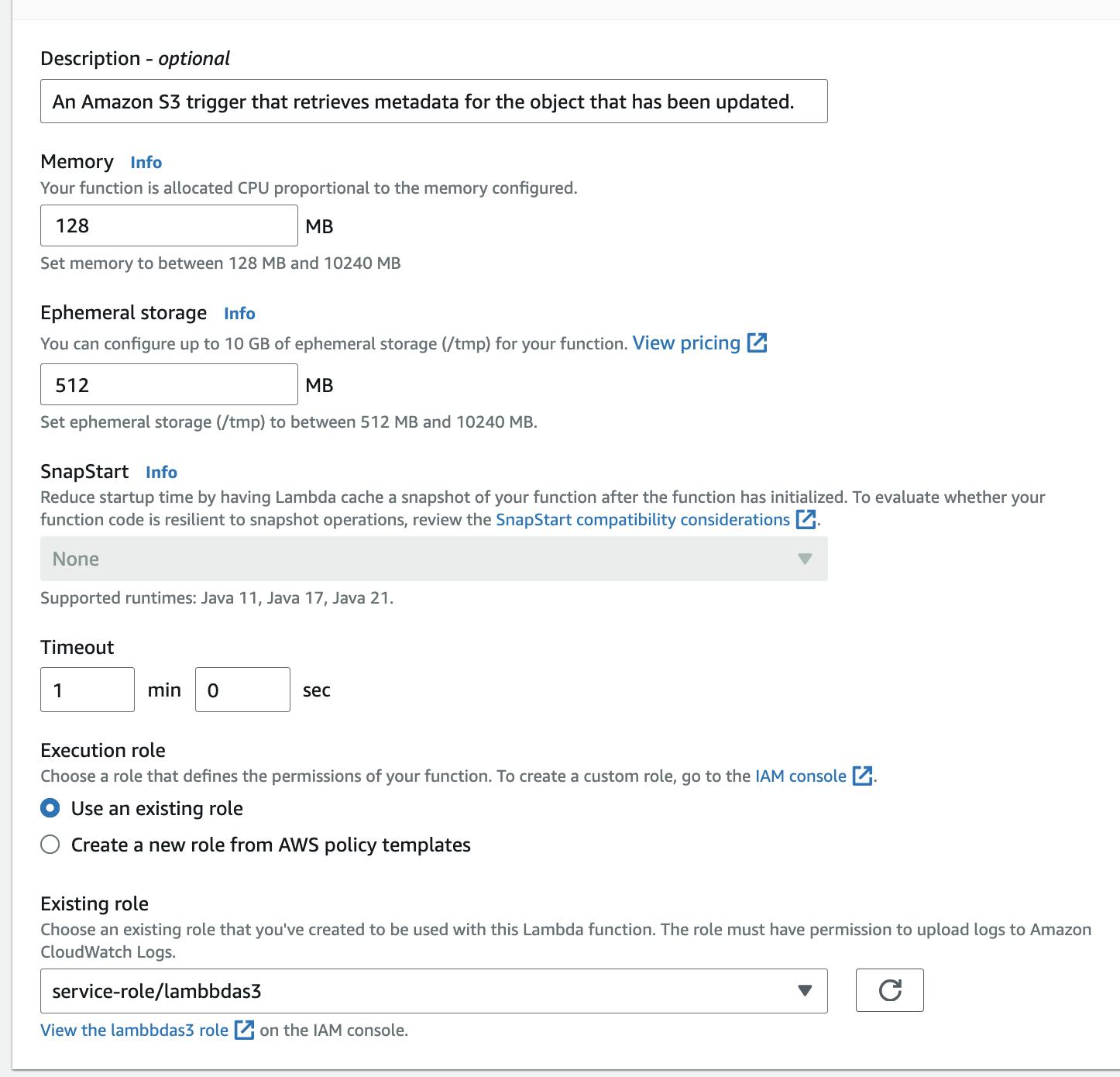
Key Configuration Settings for Lambda:
-
- Memory: Set the maximum memory your function can use. This impacts cost, so allocate wisely.
- Ephemeral Storage: Temporary storage for files during execution. It’s cost-effective, so you can allocate generously.
- Timeout: The maximum time your function can run (up to 15 minutes). Longer timeouts increase costs.
- Role: Define permissions for your Lambda function to interact with other AWS services securely.
AWS EventBridge: Automating Scheduling
AWS EventBridge is a serverless event bus that simplifies building event-driven applications. It allows you to connect different AWS services and external applications, routing events to Lambda functions based on schedules or triggers.
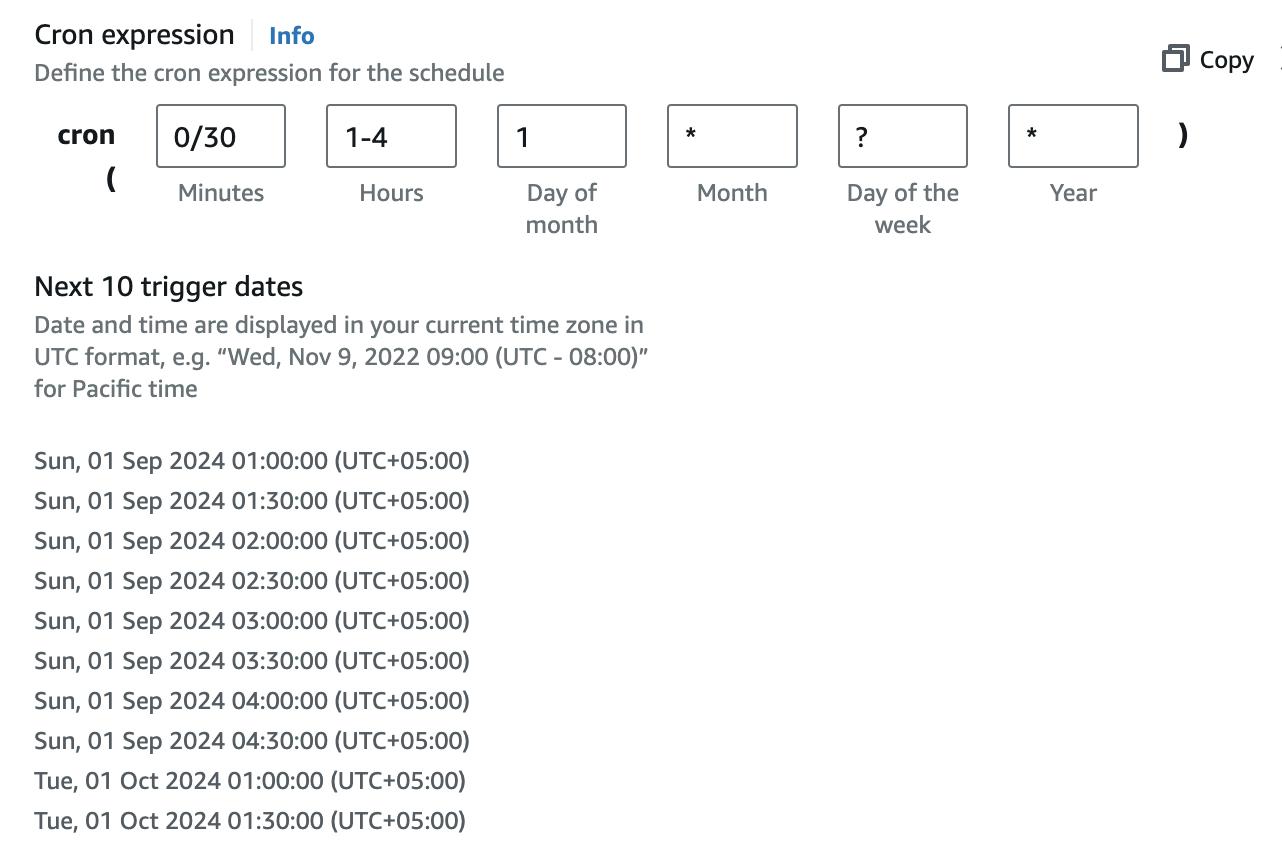
In our use case, EventBridge automates the scheduling of scraping tasks. For example, you can configure it to invoke your Lambda function every 30 minutes on the first day of the month. This ensures your scraping tasks run regularly without manual intervention.
Example Schedule:
-
- Frequency: Every 30 minutes on the first day of the month.
- Invocations: 48 per day.
- Throughput: At a rate of 10 seconds per URL, a single 5-minute Lambda invocation can efficiently parse 50 pages. Scaling this up, the system can handle a total of 4,800 URLs per day with ease. However, this is by no means the upper limit. To ensure ethical and sustainable scraping practices, you can configure multiple schedulers with a fair load policy toward the host being scraped. This means distributing requests in a way that avoids overwhelming the target server, respecting its capacity and reducing the risk of being blocked. By implementing such a policy, you not only maintain a good relationship with the data provider but also ensure the longevity and reliability of your scraping operations. Whether you’re scraping a handful of pages or thousands, this architecture adapts to your needs while prioritizing responsible data extraction.
Data Processing Strategy: Preserving Flexibility and Integrity
A common pitfall in data scraping is losing hierarchical information during processing. To avoid this, we recommend the following strategy:
-
- Save Raw JSON or Less Processed CSV: Preserve the original data structure for future reprocessing.
- Reprocess Data with AWS Glue: Use AWS Glue, a fully managed ETL service, to clean and transform your data.
- Scale with Apache Spark: For large datasets, leverage Apache Spark on AWS Glue to distribute processing across multiple nodes.
This approach ensures data integrity, flexibility, and cost efficiency. For instance, if you discover inconsistencies in your data (e.g., missing values in sub-categories or calories), you can reprocess the raw data without hitting third-party services again.
Suggested Model
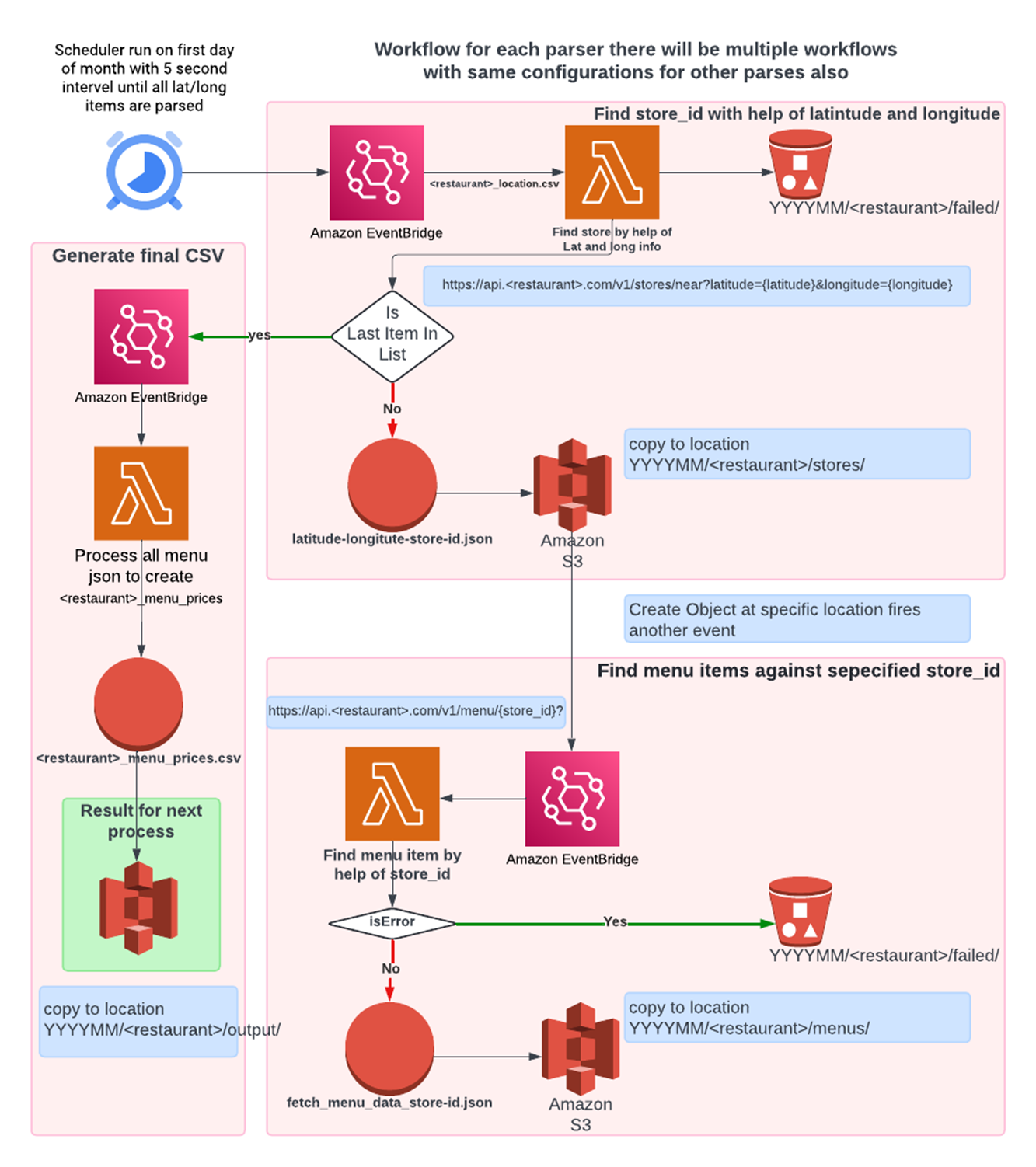
To ensure seamless and scalable execution, multiple schedulers were configured in AWS EventBridge. Each scheduler is designed to trigger an AWS Lambda function, passing specific parameters to guide the scraping process. The Lambda function processes these parameters, extracts the required data, and saves it to an S3 bucket. Upon completion, the function invokes another event. This event notifies EventBridge that additional data is available for processing, prompting it to invoke another Lambda instance with new parameters.
This cycle continues iteratively until all data has been processed. Once the execution is complete and no further data remains to be processed, the system gracefully halts, ensuring no unnecessary invocations or resource usage. This event-driven architecture not only automates the workflow but also ensures efficient resource utilization and scalability, making it an ideal solution for large-scale data extraction tasks.
The data generated through this process will be seamlessly managed by AWS Glue, a fully managed ETL (Extract, Transform, Load) service. AWS Glue will aggregate, clean, and transform the raw data into a structured format, enabling efficient mass asset generation. These processed datasets can then be readily consumed by any data warehouse, facilitating advanced analytics, reporting, and decision-making. By leveraging AWS Glue, the system ensures scalability, reliability, and seamless integration with downstream data platforms, making it an ideal solution for handling large-scale data workflows.
Why Not Use EC2? The Case for Serverless
While EC2 instances are powerful, they’re not ideal for intermittent tasks like web scraping. Here’s why:
-
- Over-Provisioning Resources: EC2 instances are designed for long-running tasks, leading to wasted resources and higher costs.
- Manual Management: Starting and stopping instances manually adds complexity and overhead.
- Cost Inefficiency: You pay for idle time, which is unnecessary for sporadic scraping tasks.
In contrast, AWS Lambda offers:
-
- Automatic Scaling: Handles varying demand seamlessly.
- Pay-as-You-Go Pricing: Charges only for actual usage.
- No Server Management: Focus on your code, not infrastructure.
-
Cost Comparison:
For 50,000 hits per month, Lambda costs approximately $1.25, while an EC2 instance would cost significantly more due to idle time and over-provisioning.
Handling IP Blockages and Failures
Web scraping often leads to IP blocks, disrupting operations. With AWS Lambda, each invocation uses a different public IP from AWS’s pool, reducing the risk of blocks. This is a significant advantage because:
-
- New IP on Every Container Spawn: Each time a new Lambda container is created, it gets a fresh public IP from AWS’s pool. This minimizes the chances of being blocked by providers, ensuring uninterrupted scraping operations.
- Focus on Publicly Available Content: Parse RSS feeds and HTML pages, which are less likely to trigger blocks.
Additionally, you can:
-
- Implement Failure Notifications: Use CloudWatch to log errors and notify stakeholders via email.
Automating Parser Testing
To ensure your parsers are working correctly, automate testing with the following steps:
-
- Gather URLs and Parsers: Create a list of URLs and their corresponding parsers.
- Send HTTP Requests: Use an HTTP client to check accessibility.
- Log Results: Store success/failure details in a structured format.
- Generate Reports: Summarize results for review.
The Competitive Edge: Pricing Data by Date and Time
In the restaurant industry, having access to competitor pricing data by date and time across different locations can provide a significant competitive advantage. This data can help you:
-
- Analyze Trends: Identify pricing patterns and trends over time.
- Optimize Pricing Strategies: Adjust your pricing dynamically based on competitor actions.
- Target Marketing Efforts: Focus on areas where competitors are underperforming
By leveraging AWS Lambda and EventBridge, you can scrape and process this data efficiently, ensuring you always have the latest insights at your fingertips.
Next Steps: Introducing an Orchestrator
While the current architecture is robust, it lacks failover handling and mid-execution control. The next step is to introduce an orchestrator to manage execution flow, handle failures gracefully, and provide better control over the process.
Conclusion: A Scalable, Cost-Effective Future
By leveraging AWS Lambda and EventBridge, we’ve built a scalable, cost-effective solution for scraping restaurant menu data. This architecture not only addresses the challenges of traditional methods but also provides flexibility, reliability, and automation. Whether you’re processing thousands of URLs or experimenting with data, this system ensures you’re always ahead of the curve.
