In the world of search engines, the goal is always to provide users with the most relevant and helpful results. Traditional search engines, rely on keyword matching and other algorithms to return results. However, these methods have limitations when it comes to understanding the context and intent behind a query. This is where Retrieval Augmented Generation (RAG) comes in.
What is Retrieval Augmented Generation?
Retrieval augmented generation (RAG) is a technique that supplements text generation with information from private or proprietary data sources. It combines a retrieval model, which is designed to search large datasets or knowledge bases, with a generation model such as a large language model (LLM), which takes that information and generates a readable text response.
Retrieval Augmented Generation (RAG) stands as a beacon of innovation in enhancing search relevance. By seamlessly integrating additional data sources, RAG enriches the output of Large Language Models (LLMs) without the need for extensive retraining. This augmentation goes beyond the LLM’s original knowledge base, incorporating new information from the web, proprietary business contexts, or internal documents, thus elevating the model’s responses. Particularly impactful for question-answering and content generation tasks, RAG empowers generative AI systems to craft more precise and contextually aware responses. Through the implementation of semantic or hybrid search methods.
Benefits of RAG in Elasticsearch
Enhanced Relevance: RAG significantly improves the relevance of search results. This ensures that users receive more accurate and contextually appropriate responses to their queries.
Augmented Knowledge Base: RAG supplements the original knowledge base of Large Language Models (LLMs) without the need for retraining. This allows LLMs to stay updated with new information from various sources, ensuring that their responses remain relevant and up-to-date.
Improved User Experience: With RAG, users can expect a more engaging and informative search experience. The ability to provide contextually rich responses enhances the overall user satisfaction and encourages further exploration.
Efficient Information Retrieval: RAG streamlines the process of information retrieval by leveraging retrieval methods to understand user intent better. This leads to faster and more accurate search results, saving time and effort for users.
Flexibility in Response Generation: RAG enables generative AI systems to use external information sources to produce responses that are more accurate and context-aware. This flexibility allows for a wide range of responses, from simple answers to complex explanations, catering to diverse user needs.
Future trends of RAG
Personalization Prowess: RAG models will evolve to become even more adept at personalization, tailoring responses to individual users’ preferences and needs. Whether it’s recommending content or assisting virtual assistants, RAG will offer a more personalized and intuitive experience.
User Empowerment: Users will have more control over how RAG models behave, allowing them to customize their interactions and get the most relevant results. This level of customization will empower users to shape their search experiences according to their unique preferences.
Seamless Scalability: RAG models will become increasingly scalable, able to handle vast volumes of data and user interactions with ease. This scalability will enable RAG to be deployed in a wide range of applications, from large-scale enterprise solutions to personalized consumer applications.
Hybrid Harmony: The integration of RAG with other AI techniques, such as reinforcement learning, will result in hybrid models that are even more versatile and contextually aware. These hybrid models will be capable of handling diverse data types and tasks simultaneously, offering a more holistic approach to information retrieval.
Real-Time Readiness: RAG models will become faster and more responsive, enabling real-time deployment in applications that require rapid responses, such as chatbots and virtual assistants. This real-time capability will enhance user interactions and drive greater efficiency in information retrieval.
Implementing Retrieval Augmented Generation (RAG)
Prerequisite
Ingest private data into Elasticsearch with the necessary mapping.
Mapping:
POST search-elastic-docs/_mapping
{
“properties”: {
“title-vector”: {
“type”: “dense_vector”,
“dims”: 768,
“index”: true,
“similarity”: “dot_product”
}
}
}
Create an application using the image architecture data flow.
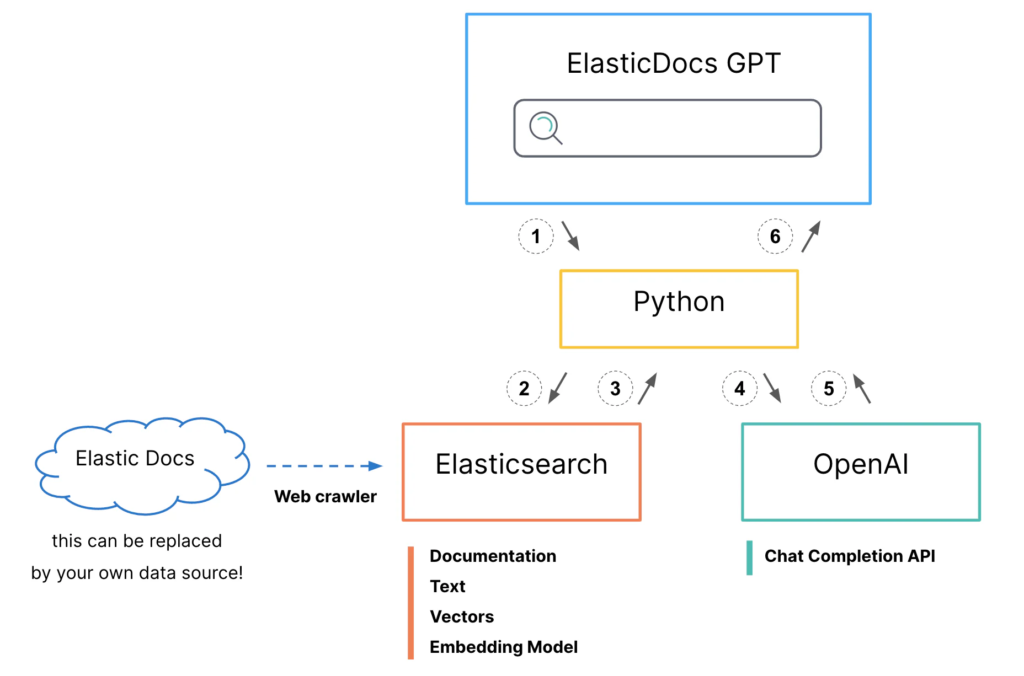
- Python interface accepts user questions.
Generate a hybrid search request for Elasticsearch
- BM25 match on the title field
- kNN search on the title-vector field
- Boost kNN search results to align scores
- Set size=1 to return only the top scored document
- Search request is sent to Elasticsearch.
- Documentation body and original URL are returned to python.
- API call is made to OpenAI Chat Completion.
- Prompt: “answer this question <question> using only this document <body content from top search result>”
- Generated response is returned to python.
- Python adds on original documentation source URL to generated response and prints it to the screen for the user.
Application code:
import os
import streamlit as st
from elasticsearch import Elasticsearch
from openai import AzureOpenAI
# gets the API Key from environment variable AZURE_OPENAI_API_KEY
client = AzureOpenAI(
# https://learn.microsoft.com/en-us/azure/ai-services/openai/reference#rest-api-versioning
api_version=“2023-08-01-preview”,
# https://learn.microsoft.com/en-us/azure/cognitive-services/openai/how-to/create-resource?pivots=web-portal#create-a-resource
azure_endpoint=“xxxx”,
azure_deployment=“GPT-4”,
api_key = “xxx”,
)
model = “GPT-4”
# Connect to Elastic Cloud cluster
def es_connect(cid, user, passwd):
es = Elasticsearch(cloud_id=cid, basic_auth=(user, passwd))
return es
# Search ElasticSearch index and return body and URL of the result
def search(query_text):
cid = ‘xxxx’ # cloud id
cp = ‘xxxx’ #elastic pass
cu = ‘xxx’ # elastic username
es = es_connect(cid, cu, cp)
query = {
“bool”: {
“must”: [
{
“match”: {
“title”: {
“query”: query_text,
“boost”: 1
}
}
},
{
“term”: {
“url_path_dir2”: {
“value”: “en”
}
}
}
]
}
}
knn = {
“field”: “ml.inference.title-vector”,
“k”: 1,
“num_candidates”: 20,
“query_vector_builder”: {
“text_embedding”: {
“model_id”: “sentence-transformers__all-distilroberta-v1”,
“model_text”: query_text
}
},
“boost”: 24
}
# knn=knn,
fields = [“title”, “url”,“body_content”]
index = ‘search-elastic-doc’
resp = es.search(index=index,
query=query,
knn=knn,
fields=fields,
size=1,
source=False)
body = resp[‘hits’][‘hits’][0][‘fields’][‘body_content’][0]
url = resp[‘hits’][‘hits’][0][‘fields’][‘url’][0]
return body, url
def truncate_text(text, max_tokens):
tokens = text.split()
if len(tokens) <= max_tokens:
return text
return ‘ ‘.join(tokens[:max_tokens])
# Generate a response from ChatGPT based on the given prompt
def chat_gpt(prompt, model=“gpt-3.5-turbo”, max_tokens=1024, max_context_tokens=4000, safety_margin=5):
# Truncate the prompt content to fit within the model’s context length
truncated_prompt = truncate_text(prompt, max_context_tokens – max_tokens – safety_margin)
response = client.chat.completions.create(model=model,
messages=[{“role”: “system”, “content”: “You are a helpful assistant.”}, {“role”: “user”, “content”: truncated_prompt}])
# print(response.choices[0].message.content)
return response.choices[0].message.content
st.title(“ElasticDocs GPT”)
# Main chat form
with st.form(“chat_form”):
query = st.text_input(“You: “)
submit_button = st.form_submit_button(“Send”)
# Generate and display response on form submission
negResponse = “I’m unable to answer the question based on the information I have from Elastic Docs.”
if submit_button:
resp, url = search(query)
prompt = f“Answer this question: {query}\nUsing only the information from this Elastic Doc: {resp}\nIf the answer is not contained in the supplied doc reply ‘{negResponse}‘ and nothing else”
answer = chat_gpt(prompt)
if negResponse in answer:
st.write(f“ChatGPT: {answer.strip()}“)
else:
st.write(f“ChatGPT: {answer.strip()}\n\nDocs: {url}“)
Conclusion
RAG, or Retrieval Augmented Generation, is a cutting-edge method that enhances search capabilities in Elasticsearch and other search engines. By combining the strengths of retrieval and generation, RAG offers search experiences that are more relevant, flexible, and user-friendly. As AI and natural language processing technologies continue to progress, RAG is expected to play an increasingly vital role in improving search and information retrieval systems. This innovative approach to search technology opens up new possibilities for discovering and interacting with information, leading to more meaningful and enriching search experiences.
If you want any help regarding Retrieval Augmented Generation feel free to contact us

